概述
Apache kafka是一个分布式的基于发布订阅的消息系统,它具备快速、可扩展、可持久化的特点,它的最大的特性就是可以实时的处理大量数据。
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
可扩展性:kafka集群支持热扩展
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
高并发:支持数千个客户端同时读写
结构
Zookeeper:整个消息系统的协调工作,保存meta信息
Broker:每个kafka实例服务器就是一个Broker,多个Broker组成集群,可以容纳多个topic,集群里会有一个Broker选举出来作为Controller负责管理其他Broker
Topic:主题,消息的逻辑归类
Partition:Topic主题的物理上的分区,一个Topic会有多个Partition,每一个Partition对应一个文件夹,由多个Segment文件组成,消费数据的定位就是靠文件的offset位置,这里还有一个index索引文件来加快数据点的查找
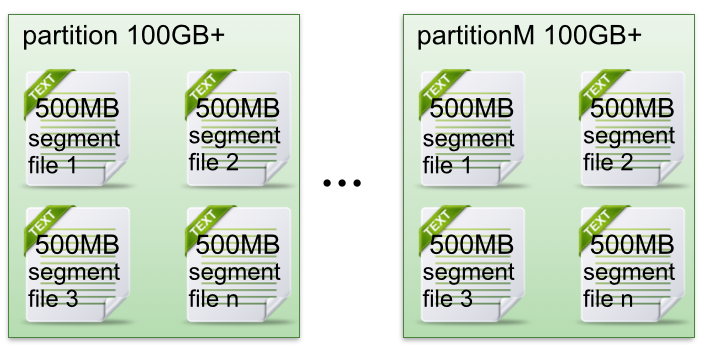

Producer:消息生产者,可以将消息发送到多个Broker上,可以采用默认分发策略也可以用户控制
Consumer:消息消费者,一个Partition只能被一个消费者消费,假如是想多个消费需要使用ConsumerGroup,在每个group里面,依然是一个Partition只能由一个Consumer消费,但是总体看是被两个group消费
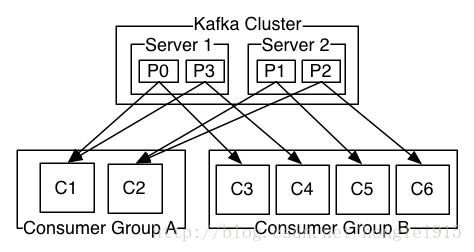
过程
- 生产者产生消息
产生消息可以指定key和分区策略类,从而使数据发送到对应的Broker的Partition分区上,当一个消息被发送后,Producer会等待Broker成功接收到消息的反馈(可通过参数控制等待时间),如果消息在途中丢失或是其中一个broker挂掉,Producer会重新发送
- Broker收消息
Broker会每一个Topic下的每个Partition建立单独文件夹,这样受到的消息会根据Topic和Partition物理隔离,而且每个Partition下的消息都是有序的,但是Partition之间不保证数据有序性。 这里Broker使用磁盘而不是内存,底层实现上是将两个IO缓冲区连接在一起
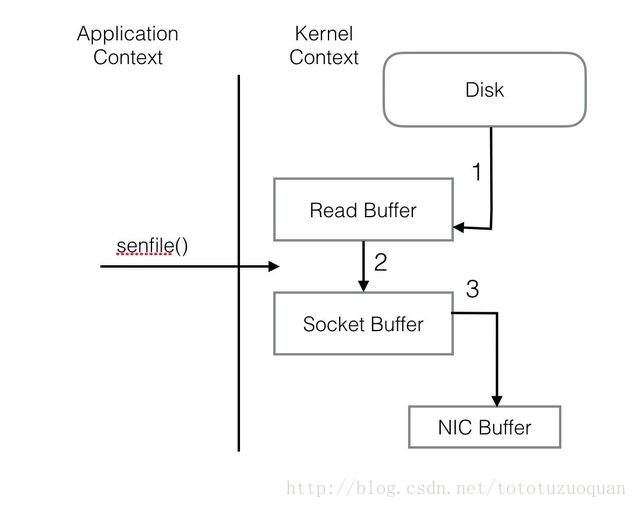
- 消费者收集消息
Broker端记录了Partition中的一个offset值,这个值指向Consumer下一个即将消费message。当Consumer收到了消息,但却在处理过程中挂掉,此时Consumer可以通过这个offset值重新找到上一个消息再进行处理。