本文介绍mysql
概述
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库,每个数据库都有一个或多个不同的API用于创建,访问,管理,搜索和复制所保存的数据。在Mysql中数据库实际是物理文件,而实例是内存上的数据库,一般是数据库与实例一一对应。
关系系数据库(RDBMS)建立在关系模型基础之上,数据保存在不同的表中,而不是一个大仓库内,这样就增加了速度并提高了灵活性。
SQL 是用于访问和处理数据库的标准的计算机语言,关键字不区分大小写。
数据库是物理文件或其他文件类型的集合,实例是MySql数据库的后台线程及一个共享内存区,在MySql中通常是实例与数据库一一对应。MySql数据库实例在凶的表现就是一个进程。
存储引擎针是基于表的而不是数据库,InnoDB是个多线程模型,不同的线程处理不同的任务,有一个内存缓冲池,最近的数据库的页会放到内存中,而且修改也是先修改缓冲池,在通过一定频率Checkpoint机制刷会磁盘。缓冲池中包含索引页、数据页、undo页等,而且允许多个缓冲池实例。
Insert Buffer、Change Buffer
修改数据的操作通过这些缓存来提高性能,辅助索引且不是唯一索引就会分批写入文件,而不是一次写入
两次写
如果数据库宕机,瞬间会导致页出现数据错误,double write可以用来恢复
自适应哈希索引
InnoDB会根据访问频率和模式自动为热点页简历哈希索引
异步IO
就是一次发出多个IO请求,然后等待所有IO操作完成,这一多个IO可以合并成一个IO操作。
刷新邻接页
刷新一个脏页的时候,假如相邻数据页也需要刷新,则一起刷新,这样多个IO可以合并成一个
文件
日志文件
错误日志:记录启动、停止、运行过程中mysqld时出现的问题
通用日志:记录建立客户端连接和执行的语句
二进制日志:记录更改数据的所有语句,还用于复制
慢查询日志:记录执行时间超过long_query_time秒的所有查询
套接字文件
在UNIX系统下本地连接MySQL可以采用UNIX域套接字方式,这种方式需要一个套接字文件。
pid文件
MySQL实例启动时,会将自己的进程ID写入一个文件中——该文件即为pid文件,由参数pid_file控制。
表结构定义文件
因为MySQL插件式存储引擎的体系结构的关系,MySQL数据的存储时根据表进行的,每个表都会有与之对应的文件。但是不论采用何种存储引擎,MySQL都有一个以frm为后缀名的文件,这个文件记录了该表的表结构定义,还用来记录视图的定义。
InnoDB存储引擎文件
表空间文件
InnoDB采用将存储的数据按表空间进行存放的设计。在默认配置下会有一个初始化大小为10MB,名为ibdata1的文件。该文件就是默认的表空间文件(共享表空间),可以通过参数innodb_data_file_path设置。如
重做日志文件
在默认情况下,在InnoDB存储引擎的数据目录下会有两个名为ib_logfile0和ib_logfile1的文件。每个InnoDB存储引擎至少有1个重做日志文件组,每个文件组下至少有2个重做日志文件。重做日志记录了InnoDB的事务日志,可以在机器宕机时用来恢复,保证数据完整性。
表
索引
索引的目的在于提高查询效率,通过不断的缩小想要获得数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件。数据库使用的是磁盘,这里系统做了优化,一次IO读取数据时会把相邻数据页读取到内存中,这些数据成为一个页(page)。
索引使用的是b+树:
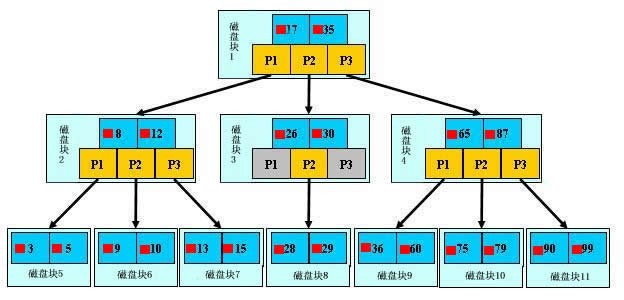
假设数据存放在叶子节点上,非叶子节点存放的是索引项。如果查找数据项29,会首先把磁盘1通过IO加载到内存,二分查找确定在17和35之间,则指向P2,然后第二次IO加载磁盘3,确定29在26和30之间,确定P2指向磁盘8,第三次IO读取到数据。
整个B+树是约低IO越少,速度越快。磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低
锁
事务
MySQL数据类型
MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
数值类型
MySQL支持所有标准SQL数值数据类型,包括严格数值数据类型(INTEGER、SMALLINT、DECIMAL和NUMERIC),以及近似数值数据类型(FLOAT、REAL和DOUBLE PRECISION)。
关键字INT是INTEGER的同义词,关键字DEC是DECIMAL的同义词。BIT数据类型保存位字段值,并且支持MyISAM、MEMORY、InnoDB和BDB表。作为SQL标准的扩展,MySQL也支持整数类型TINYINT、MEDIUMINT和BIGINT。
日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。每个时间类型有一个有效值范围和一个”零”值,当指定不合法的MySQL不能表示的值时使用”零”值,TIMESTAMP类型有专有的自动更新特性。
字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。
CHAR 和 VARCHAR 类型类似都是字符流,但它们保存和检索的方式不同。CHAR是固定长度会用空格补位,查询时,尾部的空格就会被丢弃掉,VARCHAR是变长的会用一个或两个字节来存长度,所以空格不丢。而且检索方式和存储容量不同,VARCHAR最大容量与编码相关。
BINARY 与 VARBINARY 是二进制数据,也就是说他们是包含字节流而不是字符流,排序是基于字节的数值进行的,最大长度和char与varchar是一样的,但是定义的是字节长度,而不是字符长度。
BLOB 是字节数据,可以容纳可变数量的数据。有 4 种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。它们区别在于可容纳存储范围不同。TEXT是字符数据,有 4 种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。对应的这 4 种 BLOB 类型,可存储的最大长度不同,可根据实际情况选择。这两种排序和索引需要设置有效字节长度,后面的字节不参与排序。
Sql基础语法
查看数据库
show databases;
使用数据库
use test;
查看表
show tables;
查看表结构
desc winton
建表
create table t1(
id int not null primary key,
name char(20) not null
);
语法:
create table 表名称(
字段名 字段名类型 字段描述符,
字段名 字段类型 字段描述符
);
删除表
drop table test; 语法:drop table 表名称;
修改表
- 添加字段
alter table t1 add(score int not null);
语法:alter table 表名称 add(字段名 类型 描述符); - 移除字段
alter table t1 drop column score;
语法:alter table 表名称 drop colunm 字段名,drop colunm 字
段名; - 变更字段
alter table t1 change name score int not null;
语法:alter table 表名称 change 旧字段名 新字段名 新字段描述符
插入
- 全字段插入
insert into winton values(001,’zww’),(002,’rs’
); 语法:insert into 表名 values(字段1值,字段2值,……),(字段1值,字段
2值,……); - 个别字段插入
insert into winton(id) values(004);
语法:insert inton 表名(字段名) values(值一),(值二);
普通查询
- 单表全字段查询
select * from t1;
语法:select * from 表名; - 单表个别字段查询
select id from t1;
语法:select 字段一,字段二 from 表名; - 多表查询
select t1.id,t1.score,winton.name from t1,winton;
语法:select 表一字段,表二字段,表三字段,…… from 表一,表二,表三,……;
条件查询
- 单表条件查询
select * from t1 where socre>90;
语法:select 字段1,字段2 from 表名 where 条件; - 多表条件查询
select t1.id,t1.score,winton.name from t1,winton where t1.id=winton.id; 语法:select 表一字段,表二字段 from 表一,表二 where 条件;
嵌套查询
select name from winton where id=(select id from t1 where score=90); 语法:select 字段一,字段二…… from 表名 where 条件(查询);
并查询
(select id from t1 )union(select id from winton);
交查询
select id from t1 where id in (select id from winton);
删除
delete from winton where id=4; 语法:delete from 表名 where 条件;
更新
update t1 set score=69 where id=2; 语法:update 表名 set 更改的字段名=值 where 条件;
常用函数
- 求和
select sum(score) from t1;
注:sum(字段) 对字符串和时间无效 - 求平均值
select avg(score) from t1;
注:avg(字段)对字符串和时间无效 - 计数
select count(*) from t1;
注:count(字段名)不包含NULL; - 求最大值
select max(name) from winton;
注:max(colunm)返回字母序最大的,返回数值最大的 - 求最小值
select min(name) from winton;
注:min(colunm)返回字母序最小值,返回数值最小值
常用的修饰符
- distinct字段中值唯一
select distinct name from winton;
- limit查询结果数限制
select * from winton limit 2;
- order by 排序
select * from winton order by name;
注:默认是升序 - desc 降序
slelect * from winton order by name desc;
- asc 升序
select * from winton order by name asc;
- group by 分组
select name from winton group by name;
索引
- 创建普通索引
create index wintonIndex on winton (name);
语法:create index 索引名称 on 表名 (字段一,字段二,……); - 创建唯一索引
create unique index wintonIndex on winton (id);
语法:create unique index 索引名 on 表名 (字段一,字段二,……);
注:unique index 要求列中数据唯一,不能出现重复。 - 移除索引
drop index wintonIndex on winton;
语法: drop index 索引名 on 表名;
MySql高级查询
Group By
MySql的Java操作
分库分表
Java的事务处理
索引
BTree索引使用规则
左前缀原则:条件与联合索引从左面顺序开始匹配(可以子集),如果中间没有田间或like会导致后面的列索引使用不上。
执行计划 避免使用临时表、文件排序,应该使用索引,索引可以用于i排序和分组
mysql的sql是自动优化,决定使用哪个索引的,如果不使用,可以手动指定,避免优化。
select * from XXX use index(indexName) where (dtEndTime BETWEEN '2012-12-10 00:00:00' and '2012-12-10 08:00:00' )
锁
LOCK TABLE `table` [READ|WRITE] 解锁
UNLOCK TABLES; 引用专业的描述是 LOCK TABLES为当前线程锁定表。 UNLOCK TABLES释放被当前线程持有的任何锁。当线程发出另外一个LOCK TABLES时,或当服务器的连接被关闭时,当前线程锁定的所有表会自动被解锁。 如果一个线程获得在一个表上的一个READ锁,该线程和所有其他线程只能从表中读。 如果一个线程获得一个表上的一个WRITE锁,那么只有持锁的线程READ或WRITE表,其他线程被阻止。
online-schema-change
修改线上表结构要求很高,不能影响线上数据、不能将表锁定时间过长 目前有多种方式修改线上mysql表结构,都有一定出问题的概率,本文介绍技术相对成熟的修改表结构方法 –pt
问题描述
数据库为mysql,采用主从模式,分库分表结构,每个库有1200张相同表,每张表大约有数据几十万记录,新需求要向表增加字段,但是生产环境不能停,数据库不能离线,必须在系统运行的情况下更新表结构。不能直接alter表,这样会产生很长时间的锁,对业务影响很大,需要经过特殊处理。
上线需要先修改表结构,然后上业务代码。
refrence
- http://www.ywnds.com/?p=4442
- https://blog.csdn.net/lipc_/article/details/52854382